

吕凯风 Kaifeng Lyu
我将于 2025 年秋季入职清华大学交叉信息院任助理教授。现为普林斯顿大学计算机系的博士生,师从 Prof. Sanjeev Arora,将于今年 8 月毕业。毕业后将前往加州伯克利的 Simons 研究所,担任 Modern Paradigms in Generalization 和 Special Year on Large Language Models and Transformers 两个项目的博士后研究员(Research Fellow)。
预印本论文
会议论文
Understanding incremental learning of gradient descent: A fine-grained analysis of matrix sensing
{kind=link}
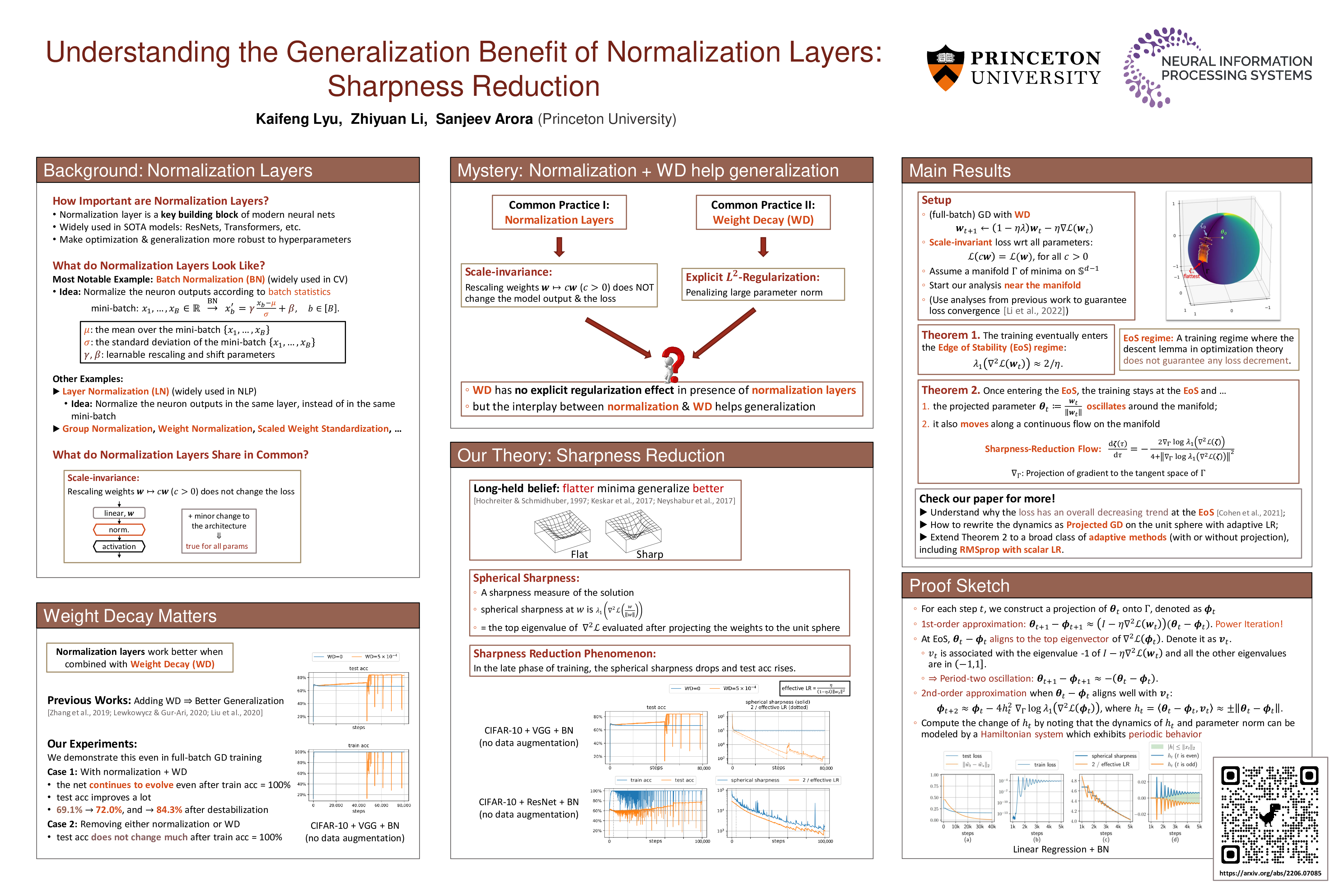
Understanding the Generalization Benefit of Normalization Layers: Sharpness Reduction
{kind=link}
New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound
Towards Resolving the Implicit Bias of Gradient Descent for Matrix Factorization: Greedy Low-Rank Learning
(按字母序排序)
Reconciling Modern Deep Learning with Traditional Optimization Analyses: The Intrinsic Learning Rate
Single-Source Bottleneck Path Algorithm Faster than Sorting for Sparse Graphs
(按字母序排序)
(默认按贡献排序;星号 * 表示贡献相同)
- 普林斯顿大学 2024 年春季学期. Teaching Assistant for COS324: Introduction to Machine Learning (taught by Prof. Sanjeev Arora & Prof. Elad Hazan).
- 普林斯顿大学 2022 年秋季学期. Teaching Assistant for COS521: Advanced Algorithm Design (taught by Prof. Matt Weinberg & Prof. Huacheng Yu).
- 普林斯顿大学 2021 年春季学期. Teaching Assistant for COS598B: Advanced Topics in Computer Science: Mathematical Understanding of Deep Learning (taught by Prof. Sanjeev Arora).
- 清华大学 2020 年春季学期. 计算机应用数学 助教(授课教师:姚期智教授).
- 清华大学 2019 年春季学期. 分布式计算:基础与系统 助教(授课教师:陈卫教授).
Professional Services
- Organizer, NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning (M3L).
- Conference Reviewer: ICML (2020-2023), NeurIPS (2020-2023), ICLR (2022-2024), TPAMI, COLT (2020), AAAI (2020), KDD (2022).
- Journal Reviewer: TMLR, JMLR, TPAMI, AIJ.
- Organizer, Yao Class Seminar, Tsinghua University (Fall 2019, Fall 2020, Spring 2021).